Originally written circa 2023-07-03. Revised 2024-04-19.
I think it’s worth it to bring up these terms since I’ve seen them be conflated in a few places. These terms crop up when analyzing settlement protocols, but are especially important when considering L2 protocols, bridges, and similar kinds of systems.
Protocol risks are the most tricky risks for a crypto protocol. These kinds of risks are absolutely essential to properly spec out when describing the trust model for a protocol, and are very closely tied with how it works.
So what do these kinds of risks look like? The most straightforward way to conceptualize them is in terms of how assets can be bridged from an origin settlement domain to another settlement domain. Typically, assets are locked in some way with a contract on an origin ledger, and then proxies are issued on another ledger that interacts with the origin ledger contract.
There’s lots of different protocols that must be analyized under this kind of framework:
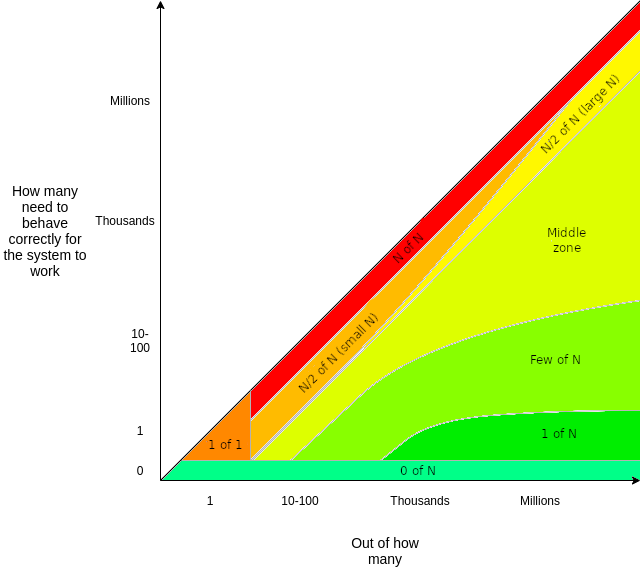
The thing to pay attention here is the number of parties with particular responsibilities, the kinds of responsibilities, and what goes wrong if the systems strays outside those requirements. Vitalik Buterin has an article that describes trust models more abstractly, going over some of the above points, linked here. I want to share this image from that article as it broadly classifies different models by optimality based on honest vs dishonest parties.
What we care about when we talk about protocol risks are the assumptions the protocol relies on to achieve its purported goals, and how likely they are to be violated to push the protocol to enter a failure condition. We also care about what these failure conditions are and what their impacts are, if there’s some graceful degradation of service that’s possible. Let’s go over a few examples.
A common critique of Lightning is its liveness requirement. It is possible for a counterparty to have the opportunity to steal funds if you drop offline. If you drop offline, then your counterparty can publish a revoked unilateral closure transaction, wait for the cooldown timelocks to expire, and steal funds that they had in the past. But this attack is extremely rare in practice due to the surrounding game theory. It’s impossible for your counterparty to know that you’re really offline and unable to issue the justice transactions that would normally be used to recover your funds if they published a revoked state. There’s also the possibility you’re using a watchtower. So really, we can think of Lightning really as being secure this way:
security:
counterparty honest
OR sufficient liveness of self
OR sufficient liveness of 1 of <a dozen or so watchtowers>But depending on the operating principle of the protocol, they may not have such forgiving failure conditions. The simplest possible validium requires that the sequencer(s) publish the contents of batches in order for users to be able to recover their funds if the sequencer goes offline or censors normal withdrawl transactions. This is why proposed designs tend to include a “data custodian” role, where a large set of pre-established parties attest that they’ve been provided with the contents of the batch by the sequencer so that they can provide it to users if requested, before the batch gets accepted by the host contract. This gives a weak notion of “data availability”. We can draw these conditions out as following:
availability:
liveness of sequencer
AND (liveness of t of <n custodians>)
security:
1 of <n custodians>If enough data custodians go offline and fail to attest, then the validium can no longer make progress. This means users can still withdraw funds through the forced withdrawal scheme, but they can no longer make normal transactions within the validium ledger. The trust model is violated, but in a way that causes a denial of service (an availability failure) rather than denying access to funds (a kind of security failure).
But a worse failure mode is if custodians do keep attesting to batches, but they all collude to refuse to provide it (or are similarly not actually recording the batch contents). This means that from the perspective of the host chain, the validium is still making progress, but users are unable to see the current state of the validium ledger and are unable to force-withdraw their funds. Presumably, in an attack like this, the sequencer would use their funds as a hostage and say “sign a transaction giving me 20% of your funds and I’ll let you withdraw the 80%”. While not technically allowing theft of funds, this would still constitute a kind of security failure. Rollups don’t have this kind of issue since they rely on the host chain to do data availability, which comes at a higher cost and sets a fee floor.
A “bridge” typically refers to a protocol that issues an asset on an unrelated foreign ledger. The most common way that these work is by having a moderately large set of cosigners (at most, a couple dozen) that effectively operate as oracles about requests to move founds around on either side of the bridge. And as a result, if some threshold of them turn malicious or are corrupted, they do have the ability to steal funds. With a very large and disparate set of parties cosigning the bridge, this becomes less of an issue since it would be difficult for them to collude. Most attacks have been on bridges with a very small number of cosigners (<20, with some as few as 5). Better bridges involve having smart contracts on both sides of the bridge that do light client sync for the other chain. But this can be very costly to run and often impose long transfer delays (as long as a few hours) to cope with the potential for reorgs that might reverse seemingly-settled transactions.
Why would someone choose a worse protocol trust model over a better one? It depends on numerous factors. Maybe the risks are nonissues for the parties involved, like with crypto exchanges running Lightning channels between each other. Maybe a use-case is involerant of high fees. Maybe we really do have good trust in some party to behave correctly, trust established through other means. In Bitcoin’s case, bridges from Bitcoin to other protocols are limited by the expressivity of its scripting language, so limitations on the environment can impose restrictions on maximum possible security.
Governance risks are a bit slipperier. Governance risks usually come from additional features that implementations of a protocol add, beyond what’s strictly necessary from a “pure” instantiation of the protocol. The main example of these being with rollups in the Ethereum ecosystem. Most deployed rollup protocols today are being managed by startups that, to upgrade the system to newer versions and satisfy their investors by maintaining control over the system, have some kind of special privilege over the protocol. These aren’t entirely nefarious, there are good justifications for it.
The best way to deal with governance risk is just not to have it. This is sometimes an entirely valid choice. Lightning does this, and it makes plenty of sense since Lightning is not a consensus system. There’s no global state that needs to have deliberation over it. Rai, a soft-stable coin that functions similar to MakerDAO but with a floating exchange rate also does this, as it was meant more as a proof of concept. But there are a number of reasons that it may be desirable to have a governance mechanism that can “break the rules” in a controlled way.
Having very tight limitations on the capacity of the governance mechanism is another way of dealing with it. Suppose there’s some parameter in the protocol (like controlling throughput rates, fees, cosigner set sizes, etc.). We can say that governance can control this value, but it can only change at a certain rate and is never allowed to stray outside some safe bounds. One crude example of this is the gas limit in Ethereum, which can be changed up or down by a maximum of 1/1024 of its current value by every block proposer, within some hardcoded bounds.
This is basically how the separation of powers in real-world government constitutions works. The US Federal Reserve Board sets interest rates and manages some reporting requirements from commercial banks, but they are fairly limited in what else they’re allowed to do. They simply are not given the authority.
Or when more involved upgrades are necessary (like being able to upgrade rollups, as mentioned earlier), a bicameral structure may be acceptable. Trusted community members must mutually agree on an upgrade to propose, but it only can go into effect is accepted by a supermajority of some larger, more anonymous set of voters. This could be sibylable, but it requires a high degree of collusion to force through unpopular upgrades.
If a malicious change is approved by a governance system, then it could be designed such that there’s a time delay before it goes into effect and give time for honest users to raise the alarm and allow people to exit from their involvement in the protocol before the negative change goes into effect, without ever actually being impacted by the negative change.
The key thing to remember with governance risks is that they tend to be artificial, and aren’t a manifestation of some formal restriction in the protocol. But since they’re artificial, we can have more sophisticated ways to cope with and manage them.
We should be precise with our language and when we critique things, we should know what we’re actually critiquing. It’s completely valid to critique Arbitrum for peculiar initial governance token distribution, but it’s wrong to ascribe failings of their implementation of the concept as failings of rollups in general. (Related article.)
As I outlined before, there’s a big desire for the startups backing these projects to have a hand in development and make upgrades straightforward to manage. Corporate agendas and all that. It’s also a good idea to keep some way to trigger an emergency halt if a security bug is found. This is a big “pause availability” button that sucks. Allegedly, these privileges will be given up in a few more years as these projects mature.
As far as I’m aware, Fuel is the only rollup project that’s done this, but I may be incorrect or my knowledge may be out-of-date.
I suspect that things could have turned out differently. If rollup projects were more grassroots and there was a better cross-settlement-domain-aware payment spec in the Ethereum ecosystem, that the norm for deploying upgrades could have been to simply deploy a new instance of the protocol and allow users to migrate over on their own. But due to the appeal of DeFi and the complete lack of good interop schemes, it became more practical for these startups to go in a different direction. That, and of course, VC’s demand to maintain control over things. L1 blockchains can deploy upgrades by having a flag day or some other socially-based signalling and keeping the coordination out-of-band and in the real world, but we don’t have that luxury when on-chain.
The key point to observe here is that protocol risks arise from the cryptography and game theory at play in a protocol, but governance mechanisms arise from the social needs that us humans want to place around these kinds of protocols to cope with future anticipated needs and unknowns. Determining the effectiveness of a governance mechanism is less of a question of security than it is a question of sociology or philosophy. Nonetheless, we should still seek to moderate the demands of the different needs placed on us and strive to improve.
There’s also the concept of “counterparty risk” and “credit risk” that don’t really apply here. They’re extremely difficult to cope with without a strong notion of identity that maps onto the real world in a way that governments will respect in order to enforce contracts. So we tend to design blockcahin systems to not rely on them, and don’t build systems that would necessarily rely on them. Insurance is an example of these.
There’s also technical software risks. Software has bugs. Compilers are software, and they have bugs. Hell, even hardware has bugs. More complex pieces of software are more likely to have more bugs. If something that crosses settlement boundaries has bugs, it can lead to inconsistent state across the settlement domain, and can lead to loss of funds. But it is possible to formally verify software and produce a proof of its correctness, which every piece of software (like crypto software) should aim to do eventually. This kind of risk is something that governance mechanisms can be used to gracefully recover from and limit damage.